How Shepherd Accelerated Underwriting with a Smarter Form Management System

TLDR:
- Context: We needed a scalable solution to select terms and conditions for policies, aiming to increase underwriter velocity and enable us to bind more policies.
- Results:The engine achieved 90% accuracy, saving us hundreds of hours, reducing errors, and making the underwriting process faster and more efficient.
- Actions:We built a highly customizable, user-friendly rules engine to automate and streamline the selection process.
One of the biggest challenges in insurtech is ensuring that negotiations between brokers and insurers – where both parties agree on what will and won’t be covered – are accurately reflected in the documents that ultimately result in an insurance policy. Managing the legal language and terms can be complex, even for a single deal. Insurers must answer questions like: “Can we cover this risk in a given jurisdiction?”, and if so, “Should we use a standard legal template or a custom template?” This complexity intensifies when negotiating and closing hundreds of policies every month across different states, where precision and efficiency become crucial to winning.
So how does Shepherd keep all of this information straight? Enter the Shepherd Rules Engine.
What Forms Are and Why They Matter
Let’s take a step back. Underwriting is the process of evaluating risk to decide whether to offer a proposal for an insurance policy. Underwriters assess aspects like loss performance, legal environment, exposure, broker requests, and appetite to decide:
- Should we insure this risk?
- What’s the right price for the insurance policy?
The result is a legally binding policy composed of forms and endorsements that outline exactly what’s covered and what’s not.
Forms are the backbone of every insurance policy. A form is a standardized document that outlines specific terms, conditions, or clauses in a policy. They help underwriters and insurers define what is covered, what isn’t, and any additional obligations or exclusions that apply to the policyholder.

Every risk in commercial insurance is unique. While standard industry forms cover many risks, others require tailored forms based on location, project type, and state-specific regulatory requirements. For example, a project in California may require earthquake coverage forms, while a project in Florida might include forms related to hurricane risk.
Forms fall into two categories:
- Coverage Forms: Define fundamental terms of coverage.
- Endorsements: Modify or add to the policy’s terms.
Selecting the correct forms is a massive challenge as forms vary based on jurisdiction, project type, and broker-specific requests. At Shepherd, our database contains over 3,000 forms across different products. As we scaled, deciding which forms to use quickly became a bottleneck in our underwriting process.
Key Challenge: Underwriters Bottlenecked by Compliance
As Shepherd grew, we started to see firsthand why form management can be such a problem at scale.
- Unlocking Revenue: Our underwriting team was sometimes completely blocked due to reliance on manual processes around form selection. Each form needed to be individuallyreviewed and approved by compliance officers, creating a massive roadblock and ultimately delaying closing deals.
- High Variability: Each policy requires unique forms tailored to its exposure, location, and coverage type.
- Manual Processes: Picking the proper forms involved a LOT of manual work, naturally leading to errors and delays.
- Compliance Risk: Incorrect or missing forms can lead to regulatory violations and disputes.
Prior to our solution, form selection was a completely manual process, with underwriters relying on compliance officers for guidance on every single deal. All the knowledge was tribal, and no standardized system was in place. Slack became the go-to tool for deal approvals, with nearly every policy being side-channeled for compliance review.


As we grew rapidly, this manual process became a significant roadblock to our company's growth, with our compliance team spending hundreds of hours reviewing and verifying forms before releasing a quote. With over 2,000 forms in play for primary policies alone, it quickly became the most significant bottleneck in the underwriting process. This delayed turnaround times for the broker, increased the risk of human error, and directly hindered revenue growth. The process wasn’t just inefficient; it was unsustainable, putting unnecessary strain on both teams.
Automation to the Rescue
We knew we needed a better way, and automation was the obvious solution. That’s where the **rules engine** came in—a newly developed capability within Shepherd’s Underwriting Platform that empowers compliance officers to define rules for form selection directly.
So what is a rules engine? At its core, a rules engine is software designed to automate decision-making by applying predefined rules to input data. These rules are typically structured as “if-then” statements. For instance, “If the policyholder resides in CA, then include a California state-specific form.” By automating decisions, rules engines allow companies to process large datasets quickly and accurately, improving customer experience and reducing operational costs.
Rules engines don’t only just solve engineering problems; they can be enhanced to provide user-friendly interfaces, enabling non-technical teams to configure and manage rules independently—dividing the power to the business users who know best in an easy, digestible interface.
Many tech companies have successfully implemented rules engines to tackle similar challenges, from on-call workflows to analytics and event tracking, companies use rules engines to make quick decisions across large data sets.
By automating the form selection process, we unlocked UW velocity and accelerated revenue because of the following:
- Save compliance officers and underwriters from hours of repetitive work.
- Speed up proposal generation and policy issuance.
- Minimize errors and compliance risks.
While building out a solution, we adhered to three guiding principles:
- Easy to Use:The system had to be simple and intuitive for Shepherd’s compliance officers and Insurance Leaders.
- Accurate:We aimed to automatically select 90% of the correct forms needed on a policy with a click of a button.
- Flexible:Business needs change, so the solution needed to empower business users to adjust the rules without relying on engineers whenever something shifts.
By automating the form selection process, we revolutionized how forms are managed.
After Automation: Accelerated Underwriting
Automation accelerated UW velocity by achieving more than 90% accuracy in form selection. Underwriters can now trust the system to deliver the majority of the correct forms, eliminating the need for compliance officers to review every policy by hand manually. Compliance officers have gained increased confidence and peace of mind in compliant proposals, allowing them to focus on higher-leverage work.
As a foundation for our compliance operations, we’ve built a centralized form management system that transformed how forms and endorsements are handled. Compliance officers no longer need to answer repetitive questions or rely on ad-hoc Slack conversations. Instead, they can codify their knowledge directly into the system by creating rules. This ensures consistency, reduces errors, and increases transparency across all Shepherd's insurance products.
The impact has been transformative. Faster underwriting workflows mean fewer delays, enabling more deals to move through our pipeline. By reducing turnaround times, we’ve unlocked significant revenue opportunities, ensuring our team is better equipped to handle more business as we continue to scale at a fast pace.
Engineering the Solution
The Shepherd Rules Engine is a system designed to evaluate specific conditions and take automated actions based on the results. Here's how it operates:
Condition Evaluation: The engine checks predefined conditions such as:
- Is this project in California?"
- Does this policy have fleet vehicles in Texas?"
Action Execution:Based on whether these conditions are true or false, the engine decides the appropriate action. For instance:
- If the condition is true, the relevant form is added to the deal.
- If the condition is false, the form is excluded.
By automating these checks and actions, the rules engine ensures accuracy and reduces manual effort.
Challenges We Overcame
Creating a robust rules engine isn’t just about functionality; it’s about designing a system that excels in efficiency, scalability, and user empowerment. In the context of an insurtech rules agent, we needed to make sure that our software was able to quickly and accurately identify all forms that could be relevant to any given deal. This meant we needed to ensure:
1. Accuracy
Our primary goal was to ensure the engine could automatically select 90% of the necessary forms with a single click, significantly increasing underwriting velocity and unlocking more revenue for Shepherd. We didn’t aim for 100% automation due to the following:
- Broker-Specific Requests:Certain forms must accommodate unique broker needs that fall outside standardized rules.
- Deal-Specific Variations:Some policies require one-off adjustments or custom forms that don’t follow predictable patterns.
- Complex Rules: A small subset of forms involves intricate rules that our system cannot yet process effectively.
2. Bridging the Knowledge Gap
We needed a solution that empowered insurance professionals to encode their business expertise directly into the tool, avoiding reliance on engineering for frequent data backfills around nuanced compliance knowledge that we, the engineers, didn’t have.
3. Scalability
Scalability meant creating a system that could seamlessly extend to other parts of the business as we grow and expand into new products, such as Builders Risk. The system needed to support a range of data sources from the Underwriting Platform to minimize the need for continuous engineering support.
4. Speed
With thousands of forms to process for every deal, speed was critical to enhancing the underwriting experience (UWX) and unlocking more revenue for our business.
The Rules Engine GUI: Empowering Users with Flexibility
We developed a user-friendly rules engine GUI designed specifically for insurance professionals.
With this intuitive interface, the user can create, test, and refine rules—transforming their expertise into automated, deterministic solutions. The result? Forms will be correctly populated based on rules defined by business owners, knowing the system will handle the complex decision-making process behind the scenes. We’ve put the power of automation directly into the hands of those who know the business best.
The Data Layer: Blob Store vs Relational Database
We considered using a Blob Store, such as S3, because of its scalability and cost-effectiveness. However, its lack of querying capabilities for structured data and the additional complexity of updating rules made it less suitable for our needs. Since our rules required efficient querying and frequent updates, we decided on Postgres.
Postgres not only integrated seamlessly with our existing infrastructure, but it also provided the structured data querying and update efficiency we needed to scale our engine. While we recognized potential challenges with schema flexibility as the engine evolved, its overall capabilities made it the best fit for our requirements.
Initially, we stored everything in a JSON column within a single rules table, thinking it would provide flexibility with nested structure, reduce the number of joins in our queries, and make it even easier to integrate with our open-source library. However, as we iterated on the architecture and began expanding the system, we realized that this approach tightly coupled the flexibility of the engine to the rule itself. As the rules became more complex, updating the JSON column became cumbersome, and we saw limitations in how easily we could adapt the system for future enhancements, such as nested conditions.
To overcome these challenges, we split the data into two tables—rules*and condition_fields. This change allowed us to better organize and manage our data, provided room for future enhancements like nested conditions, and made the engine more scalable. By separating the rules from their conditions, we ensured that our querying performance remained fast and efficient while setting up the system for future growth.
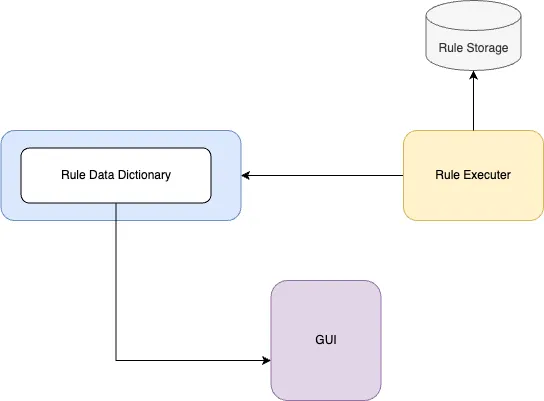
The Data Dictionary: Keeping Things Organized
>
> ```
> export const FIELD_DEFINITIONS_BY_FIELD: Record<Field, FieldDefinition> = {
> [Field.STATES]: {
> valueOptions: formattedStatesWithoutTerritoriesValues,
> productOptions: ALL_PRODUCTS,
> operatorOptions: ARRAY_OPERATORS,
> inputType: InputType.MULTI_SELECT,
> displayName: 'State',
> fact: Fact.GENERAL_QUOTE_DATA,
> path: '$.states',
> }
> ```
Finally, we needed a solidified way to define the fields our rules could use in one consolidated place.
This centralized file lists all the available fields, their values, operators, and hydrator paths, which tells our hydration service layer where to fetch the related data. It serves two key purposes:
- Consistency:Ensures every rule is built with the same reliable data.
- Ease of Use:Feeds our GUI with field options for non-technical users while guiding the engine on how to fetch data.
The data dictionary is the backbone of our rules engine. It connects the dots between user inputs, rule logic, and data retrieval, ensuring the system runs smoothly.
Rules Executer: In-house solution vs open source?
When it came to executing the rules, we had to decide whether to build an in-house engine or leverage an open-source solution like json-rules-engine. After weighing our options, we chose the open-source approach. While building a custom rules engine would have given us full control and the ability to tailor everything to our needs, it also came with significant development effort and potential scalability challenges.
The json-rules-engine struck the perfect balance for us. It allowed us to reduce development time by offering built-in features like rule prioritization, caching, and debugging. It was designed to scale, making it capable of handling complex rule sets without reinventing the wheel. Its structured JSON rule definitions made it easier to understand and integrate with our database models. Using a third party lets us focus on refining our business logic instead of spending time developing and maintaining a custom engine.
A Deeper Dive Into the Rules Execution Handler Flow
When an underwriter refreshes forms and endorsements on a quote, our backend server calls the rules engine. This process is streamlined through a series of steps:
- Retrieve Forms:** the backend fetches all the forms associated with a quote that will need to run through our rules engine.
- Evaluate Each Form: each form is processed individually through the json-rules-engine. We hierarchically evaluate the rules. Rejected Rule:This rule is evaluated first. If this condition is evaluated as true, the form is excluded from further evaluation. Mandatory Rule: If this condition is evaluated as true, the form is inserted into the selected forms for the policy.
Adding Custom Operators
While json-rules-engine offers a range of built-in operators, we needed more nuanced evaluations tailored to our rules. For example, we added a custom operator to check if all elements in a condition's field options exist in the fact values.
Here’s how we added the **CONTAINS_ALL** operator:
>
> ```
> engine.addOperator(
> operatorToOperatorValue[Operator.CONTAINS_ALL],
> (factValues: any, conditionFieldOptions: Array<any>) => {
> if (isNil(factValues)) return false;
> const valuesArray = Array.isArray(factValues) ? factValues : [factValues];
> return valuesArray.every((factValue) => conditionFieldOptions.includes(factValue));
> }
> );
> ```
Building And Executing The Rules
The rules are dynamically built into JSON objects and then fed into the json-rules-engine. Each rule comprises of:
- Conditions:Generated using buildConditions to evaluate the logic based on the input condition fields and operation.
- Event:Encapsulates what action to take if the conditions are evaluated to be true.
> ```
> const rule: RuleProperties = {
> conditions: buildConditions({
> conditionFields,
> operation,
> }),
> event: {
> type: ruleEvent.type,
> params: {
> id: ruleEvent.params.resourceId,
> message: `Executing rule event ${JSON.stringify(ruleEvent)} for quote ${quoteId}`,
> },
> },
> };
>
> ```
Once the rules are constructed, they are added to the engine for evaluation:
> ```
> engine.addRule(rule);
> ```
Fetching Data
We fetch data by dynamically adding facts to the engine during runtime. Facts represent data points the engine uses to evaluate rules, and their definitions are sourced from our data dictionary by the path field. We used a service layer mapping to the fact’s path to tell the engine which values to pass in.
Here’s how we add facts to the engine:
> ```
> await Bluebird.map(conditionFields, (condition) => {
> engine.addFact(condition.fact, async () => {
> logger.debug(`Fetching fact data for quote ${quoteId}: ${condition.fact}`);
> return await getFactFromRuleEngineCache(
> {
> quoteId,
> resourceId: ruleEvent.params.resourceId,
> fact: condition.fact,
> policyProduct,
> selectedFormIds,
> },
> ctx
> );
> });
> });
> }
> ```
Optimized Execution with Cache
Initially, our rules engine operated without caching. Every time a condition was evaluated—often involving multiple conditions per rule for a form—the database was queried to retrieve the necessary values. This resulted in a significant performance bottleneck,especially when processing complex policies with large data sets, such as primary deals.
To solve this, we implemented a cache mechanism by adding a custom wrapper that initializes a cache at the start of each evaluation and clears it after processing.
With the cache in place, we ensured that facts—fields defined in the data dictionary that determine what values to retrieve from the database—were only fetched once per quote ID. The cache is initialized at the start of each rule engine execution, and any data needed for evaluation is pulled from it rather than querying the database again. After the processing is complete, the cache is cleared, ensuring that no stale data is carried over to the next evaluation.
This simple yet effective change drastically improved performance. By reducing the number of database queries, we were able to cut form generation time from over 90 seconds to just 3 seconds, making the process much faster and more efficient. This optimization not only improved the user experience but also reduced the load on our database, ensuring that the rules engine could scale more effectively as we handled larger volumes of data.
> ```
> export const rulesEngineExecutionWrapper = async <T, R>({
> callbackFunction,
> param,
> }: {
> callbackFunction: (param?: T) => Promise<R>;
> param?: T;
> }): Promise<R> => {
> startRuleEngineCache();
> const response = await callbackFunction(param);
> clearRuleEngineCache();
> return response;
> };
> ```
Fact Execution Flow:
- Initialization:Facts are dynamically registered to the engine based on the condition fields defined in the rule.
- Data Retrieval:The engine calls the associated fact service layer when it encounters a fact during evaluation.
- Optimization:Fact values are cached during each rule evaluation to minimize database queries. See the next section for further details on our caching strategy.
The Road Ahead: Future Improvements
While our current rules engine has improved form selection accuracy, like any system, there’s always room for improvement.
Supporting Nested Conditions
Right now, our engine handles straightforward conditions exceptionally well. However, as we dive into more complex forms, we’re seeing an increasing need for nested conditions—rules that depend on other rules or contain layers of logic. For example:
- Form A: “If the project is in California and has fleet vehicles OR If the project is in California and is a RENEWAL”
Nested conditions add complexity, but they also make the engine much more powerful. We currently only support one higher-level operation [ALL, ANY, NONE] to be applied to a set of conditions. We are exploring ways to build a flexible framework to handle these situations.
Handling Dependent Rules
Another challenge we’re tackling is dependent rules. In some cases, one form’s rule might depend on another form’s rule being true. For example:
- Form A: “If the project is in California and has fleet vehicles and Form B is TRUE”
- Form B: “If the project is in California”
We currently support situations like this where our rules engine can search for the dependent form, evaluate its rules, and return the answer for Form A. However, if not carefully defined, this flexibility can easily introduce circular dependencies. For example:
- Form A is required if Form B is selected, but Form B is required only if Form A is also TRUE.
These scenarios can create infinite loops if not carefully managed. We’ve implemented guardrails to throw exceptions when circular dependencies are detected, but we’re working on making these validations more user-friendly to prevent issues at the rule creation stage.
Event-based execution
We aim to expand our engine's capabilities to handle event-based triggers, moving beyond just form selection and deselection. This shift will enable the creation of more dynamic workflows, where actions are triggered by specific events within the platform. For example, we can trigger side effects such as sending an email, creating a task for an underwriter or notifying a user when certain conditions are met. By integrating event-based execution, we can automate entire workflows, enhancing efficiency and ensuring timely responses to critical actions within the platform.
We are Hiring!
If you want to be a part of our A-Star team and contribute to impactful projects, please check out [our open roles on our careers page](https://www.google.com/url?q=https://shepherdinsurance.com/careers&sa=D&source=docs&ust=1737065760476802&usg=AOvVaw3R3LPHcYy9CGWUPK85tNN-)! We’d love to hear from you :)